Beyond the Web

Watch this (it’s only 30 seconds) and then answer these questions:
- Why are the choices presented to you by websites called your choices, when all those choices are provided by them? And why don’t you give them choices? Specifically,
- Why do you always have to accept websites’ terms?
- Why do you have no way to proffer your own terms, to which websites can agree?
- And why do you have no record of what you accepted, or when‚ or anything after you’ve made “your” privacy choices at a website?
- Why did Do Not Track, which was never more than a polite request not to be tracked off a website, get no respect from 99.x% of the world’s websites? And how the hell did Do Not Track turn into the Tracking Preference Expression at the W2C (as if you must have some kind of tracking), where the standard never did get fully baked?
- Why, after Do Not Track failed, did hundreds of millions — or perhaps billions — of people start blocking ads, tracking, or both, on the Web, and doing that so much that it became the biggest boycott in world history? And then why did the advertising world, including nearly all advertisers, their agents, and their dependents in publishing, treat this as a problem rather than as a clear message from the marketplace?
- Why would Apple’s way of making you private on your phone be to “Ask App Not to Track,” rather than “Tell App Not to Track,” or “Prevent App From Tracking You”?
- Why does the GDPR call people “data subjects” rather than people, or human beings, and then assign the roles “data controller” and “data processor” only to other parties? (Yes, it does say a “data controller” can be a “natural person,” but more as a technicality than as a call for the development of agency on behalf of that person.)
- Why are around 400 million results in a search for GDPR+compliance about how companies can obey the letter of the GDPR while violating its spirit by continuing to track people through the giant loophole you see in every cookie notice?
- Why does the CCPA give you the right to ask to have back personal data others have gathered about you on the Web, rather than forbid its collection in the first place? (Imagine a law that assumes that all farmers’ horses are gone from their barns, but gives those farmers a right to demand horses back from those who took them. It’s like that.)
- Why are we stuck in an online economy in which advertisers work constantly to grab our attention, rather than one in which our intentions as buyers run the show?
- Why, 22 years after The Cluetrain Manifesto said, we are not seats or eyeballs or end users or consumers. we are human beings and our reach exceeds your grasp. deal with it. — is that statement still not true?
Let’s go back to that video, by Paul Trevithick, of the Mee Project. The closing frame tells the whole story of our situation today:

It’s easy to blame the cookie, which Lou Montulli invented in 1994 as a way for sites to remember their visitors by planting reminder files — cookies — in visitors’ browsers. Cookies also gave visitors a way to remember where they were when they last visited. For sites that require logins, cookies take care of that as well.
What matters, however, is not the cookie. It’s what makes the cookie necessary in the first place: the Web’s architecture. It’s called client-server, and is represented graphically like this:

This design was drawn up in the era of centralized mainframes, which “users” accessed through client devices called “dumb terminals”:

On the Web, as it was in the old mainframe world, we clients — mere users — are as subordinate to servers as are calves to cows:
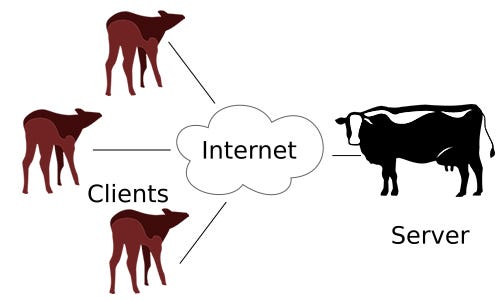
(I’ve been told that client-server was originally a euphemism for “slave-master.” Whether true or not, it makes sense.)
In the client-server paradigm, our agency is limited to what servers allow or provide for us. Our choices are what they provide. We are independent only to the degree that we can also be clients to other servers. In this paradigm, a free market is “your choice of captor.”
Want privacy? You have to ask for it. And, if you go to the trouble of doing that — which you have to do separately with every site and service you encounter (each a mainframe of its own) — your client doesn’t keep a record of what you “agreed” to. The server does. Good luck finding whatever it is the server or its third parties remember about that agreement.
Want to control how your data (or data about you) gets processed by the servers of the world? Good luck with that too. Again, Europe’s GDPR says “natural persons” are just “data subjects,” while “data controllers” and “data processors” are roles reserved for servers. In other words, the GDPR reifies the calf-cow construct.
Want a shopping cart of your own to take from site to site? My wife Joyce asked for that in 1995, when one of her sisters was one of the top people at Netscape. It was barely thinkable then and less thinkable now, 27 years later.
Want a dashboard for your life where you can gather all your expenses, investments, property records, health information, calendars, contacts, and other personal information? Joyce has wanted that too, all along. Yet still most of what we have are closed, proprietary, and largely incompatible pieces of it, served from clouds by Apple, Google and Microsoft. Plus some apps. But nothing that is fully yours.
This model is also why we have an Apple of Things, a Google of Things, and an Amazon of Things rather than a real Internet of Things.
Simply put, If it’s not thinkable by the developers and owners of the servers we depend on, it doesn’t get made.
This is why, after more than a quarter-century on the Web’s client-server ranch, it’s hard to imagine a world outside the fences: open spaces where it’s possible for each of us to not be just clients enslaved to as many servers as we deal with every day. Or, on our phones, inside every damned app.
So yes, the Web is wonderful, but not boundlessly so. It has limits. Thanks to the client-server architecture that prevails there, full personal agency is not a grace of life on the Web. For the thirty-plus years of the Web’s existence, and for its foreseeable future, we will never have more agency than its servers allow clients and users.
But a free and open digital world does exist, and it’s the one the Web runs on: the Internet. It can support a helluva lot more than the Web, with many more ways to get along and get things done.
Some perspective: Digital technology as we know it has only been around for a few decades, and the Internet for maybe half that time. Mobile phones that presume Internet connectivity everywhere have only been with us for a decade or less. Buy the Internet and phone-like personal devices will be with us for many decades, centuries, or millennia to come.
We are also not going to stop living digital lives, any more than we are going to stop speaking, writing, or using mathematics. Digital technology and the Internet are granted wishes that won’t go back into the genie’s bottle.
So it’s time to think and build outside the Web’s ranchland. Models for that do exist, and some have been around a long time.
Email, for example. While you can look at your email on the Web, or use a Web-based email service (such as Gmail), email itself is independent of those. My own searls.com email has been at servers in my home, on racks elsewhere, and in a hired cloud. I can move it anywhere I want. All the services I hire to host my email are substitutable. Despite all the mail servers I’ve had, and clients I’ve used, my email records go back to 1996. And they are mine. Not Apple’s or Google’s or Twitter’s. And that’s just one example of how we can enjoy full agency on the Internet.
[Later…] I wrote this in prep for Beyond the Web salon at Indiana University’s Ostrom Workshop that starred Ethan Zuckerman and described here and viewable here.
